What DevOps Already Knew About AI Development

In 2018, Gene Kim and John Willis released Beyond the Phoenix Project, a nine-part audio series that digs into the philosophical roots of the DevOps movement. It's an excellent supplement to The Phoenix Project. Where the novel shows the pain, the audio series explains why it hurts. But because it’s an audio companion piece, most people have never heard it.
The part that’s most stuck with me over the years is what Kim calls “the five predictable bottlenecks of software delivery.” They’re numbered 1-5, and you must solve them in order. No skipping ahead. They go like this:
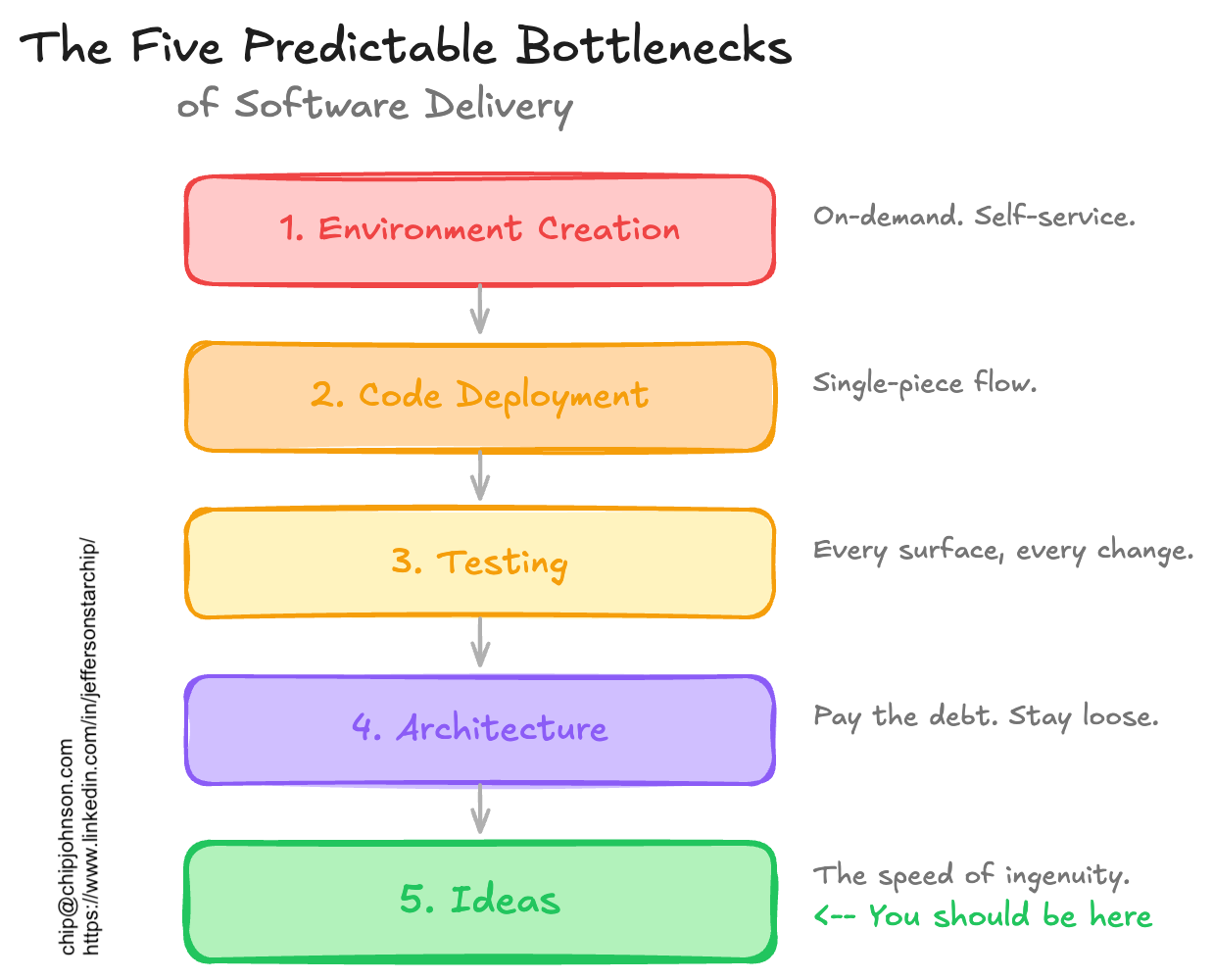
AI development doesn't eliminate these bottlenecks. It just slams you into the next one faster. Face-first.
Over the last few years, every time I've presented at a tech conference, I've included a slide on the bottlenecks. I always tell people, "If you're going to take a picture of one slide from this presentation, make it this one." It's the single most useful mental model I've found for diagnosing why a software organization is slow.
The Bottlenecks Explained
Environments
At the first bottleneck, your teams are stuck waiting for environments. Somebody has to provision the infrastructure, configure DNS, file a ticket to open the firewall, and wait. The fix to this is on-demand environment creation: press the button, get a runtime, whether dev, staging, or prod. Automate creation. Make new ones all the time, throw away the old ones. Make it self-service. Move on.
Deployment
Next is deployment. Once you can create environments, you’ll likely realize pushing code to them is its own nightmare. Too many steps, too many handoffs, too many pieces to coordinate. Kim emphasizes that teams should build their deployments as a single-piece flow.
In a factory, batch production means you make 500 units of part A, then 500 units of part B, then assemble them all at once. But batches hide defects and slow the line to the speed of the worst delay; a flaw replicated 500 times takes longer to unwind. By contrast, single-piece flow means one unit moves through every station before the next unit starts. You catch problems immediately. Nothing queues. The system moves continuously, and defects are caught and resolved quickly.
In software, the equivalent is one change, one deploy. Not ten features bundled into a release train, or a quarterly mega-release window. One commit moves through build, test, and deploy before you start the next. It does so in seconds. The goal is to make deployments so routine that they disappear from thought entirely.
Developers have traditionally resisted single-piece flow, not because they lack discipline, but because the system has historically punished it. When deploys take 45 minutes, and a failed build might page you at 2 AM, batching is rational. It’s not laziness; you’re amortizing risk and overhead. Batching is what happens when tool use is expensive and failure is loud. Developers learned to do it because the system demanded it.
Claude Code doesn’t have that instinct because it never paid those costs. When Superpowers manages implementation, it breaks work into tightly scoped tasks. Dependent tasks run sequentially. Independent tasks run in parallel, each in its own worktree. Either way, each task is a single piece moving through implementation, test, and review before completion. When parallel tasks finish, Claude reconciles the work and handles the merge. It is not batching. It is multiple single-piece flows running at once.
On the web, each session runs in its own sandboxed environment, isolated by design. Same principle. Different mechanism.
Testing
You're deploying fast, but you're shipping bugs faster. Every change surface needs a test. You need confidence that what you shipped actually works. They need to be the right tests, and they need to be fast.
Architecture
Congratulations! You've got tests, fast deploys, and on-demand runtimes for every work context. Now the codebase itself is the problem. Tech debt accumulates. Components become so tightly coupled that changing one thing breaks three others. You need to pay this all down regularly and keep things loosely coupled enough so the system can evolve.
Ideas
Here is where Kim says the bottleneck should be. When environments spin up on demand, deployments are trivial, tests are fast and comprehensive, and architecture is clean, the limiting factor becomes how fast humans can come up with good things to build. The speed of ingenuity.
That’s where you want to live, all the time.
It was a radical statement in 2018. For a lot of organizations, it still is today.
This All Still Applies to Your Agentic Coding Projects
As I’ve been getting comfortable using Claude Code on the web, connected directly to my GitHub repos, I keep coming back to Kim's framework. It maps perfectly to how agentic development projects succeed.
The bottlenecks are the same. The order is the same. And if you don't address them, you'll stall in the same places, no matter how advanced the model writing your code.
Environment Creation
Claude Code on the web can see your repo and push branches. But if you can’t actually see what it builds, you’ve got a bottleneck. The goal is a preview environment for every PR.
For frontend projects, tools like Vite paired with Netlify or Vercel give you this almost for free. Every pull request gets a deploy preview with a clickable URL. For infrastructure-heavy projects, Terraform with GitHub Actions can spin up ephemeral staging environments on demand, scoped to the branch and torn down when the PR closes.
The specifics depend on your stack, but the principle doesn’t. Regardless of how you run your coding agent, when it finishes a task and pushes a branch, you should be able to see the result running somewhere real, with a full copy of the stack, and full resource isolation. If that’s not the case, fix that first. Everything downstream depends on it.
Code Deployment
Once your preview environments exist, the question becomes, how does code get there? The answer should be the same code pipeline that deploys to production. Same mechanism, same gates, every time. A push to a branch triggers a preview. A merge to main triggers staging. A tagged release triggers production. The same code deploys it all, the only difference is the target.
Claude Code on the web already pushes branches to remote when it finishes a task. Meet it halfway. Make sure your pipeline picks up from there without human intervention.
GitHub Actions makes this straightforward. Define workflow triggers that match each stage: a push to any PR branch deploys a preview. a merge to main deploys to staging. A release tag deploys to production. Three workflows, same deployment logic, different targets. The pipeline definition lives in the repo alongside the code, so Claude can see it, understand it, and even modify it as the project evolves.
Here’s the catch: Because agents don’t batch, it’s common to have parallel tasks finishing within minutes, each opening a pull request, each triggering a preview environment. A pipeline that might have worked fine for a team of humans deploying a few times a day might buckle under an agent that treats deployment as a function call. Integration environments like staging will still serialize by design, but the concurrency pressure shows up earlier, in previews and development targets.
Your deployment pipeline will need to support concurrent builds without shared state between resources. If your automation can’t handle multiple simultaneous pushes to dev environments without choking, that’s the bottleneck.
Testing
As I wrote in my last post, Jesse Vincent's Superpowers plugin enforces real red-green-refactor test-driven development. Every change gets an executable definition of success before implementation starts.
Even with TDD enforced, though, agents will happily generate code with test coverage that looks comprehensive but tests implementation rather than observable behavior. The tests pass because the agent wrote them to pass, not because they validate anything a user would care about.
But now that you’ve built proper preview environments, you can go further. Run Playwright tests against a real deployment. Exercise actual infrastructure with integration tests. Your agent can help write these tests and handle the syntax, but you still have to specify what “working” means.
More than any other part of an agent-authored pull request, inspect the tests. Make sure they’re testing something that matters. You decide what’s meaningful, the agent writes the tests, and your CI infrastructure runs them.
Architecture
Here's where agentic coding colliding with DevOps philosophy gets interesting and dangerous.
Claude is remarkably tolerant of tight coupling. It will eat the maintenance pain of tangled dependencies far longer than any human team would. Rename a data model and watch it calmly rewrite half the repo without complaint. It doesn't miss a capitalization in camelCase. It just quietly absorbs the complexity.
This is a genuine advantage. It means you can move fast on projects where the architecture isn't ideal, because the carrying cost of that mess is temporarily subsidized by an agent that can’t get frustrated.
It is also a trap.
Tight coupling that an AI can tolerate is still tight coupling. The moment you need to hand the codebase to a human for review, audit, or onboarding, the accumulated architectural debt lands all at once. And because Claude never complained, you might not realize how bad it’s become.
Use Superpowers’ requesting-code-review skill regularly. Ask Claude to explain why it touched files that seem unrelated to the task. If the answer is "because everything is connected to everything," that's your signal. Pay the debt while you can still afford it.
The Speed of Ideas
If you’ve solved environments, deployment, testing, and architecture, you’re here. This is where you want to be.
Two weeks ago, I took my niece to see Avatar 3 and had a good thought about a project while waiting for the previews to start. Because I had Claude Code on the web connected to the repo and GitHub Actions handling the pipeline, I was able to take out my phone, type a prompt, and kick off work while I sat and shared a movie with a loved one. When the credits rolled I was able to review the PR, see working code, merge, and push to production before we got back to the car.
That’s when it all clicked into place. The bottleneck wasn’t tooling, infrastructure, or process. It was whether I had something worth building next. It didn’t matter if I was in a movie theater, at my desk kicking off three parallel sessions, or sitting on a plane with nothing but a browser tab.
The bottleneck is no longer provisioning, deploying, testing, or untangling. It’s you. How fast can you articulate what “done” looks like? How precisely can you define success? How many good ideas can you feed the system before lunch?
Kim said this is where the bottleneck should be. Now it’s on you.
